After training and testing of a learning algorithm , the best way to deploy it is not to just place it in a production environment and turn it on , hopefully that nothing will go wrong , because in reality a lot of things will go wrong !
When deploying systems you need to check certain items and how robust is your deployment strategy to deal with these items:
- Is there already an existing model in production that will be replaced?
- If there is a bug in the new deployment, Is there a quick and applicable rollback plan?
- if my model doesn’t reach the required accuracy in production , how huge is the negative consequences , and what is the best strategy to minimize them?
- How Fast will the new model be rolled out?
This is the basic list of questions and of course this list can be expanded depending on different use cases and different business areas.
Throughout this article I am going to discuss the common strategies of ML Models deployment , telling the pros and cons of each strategy.
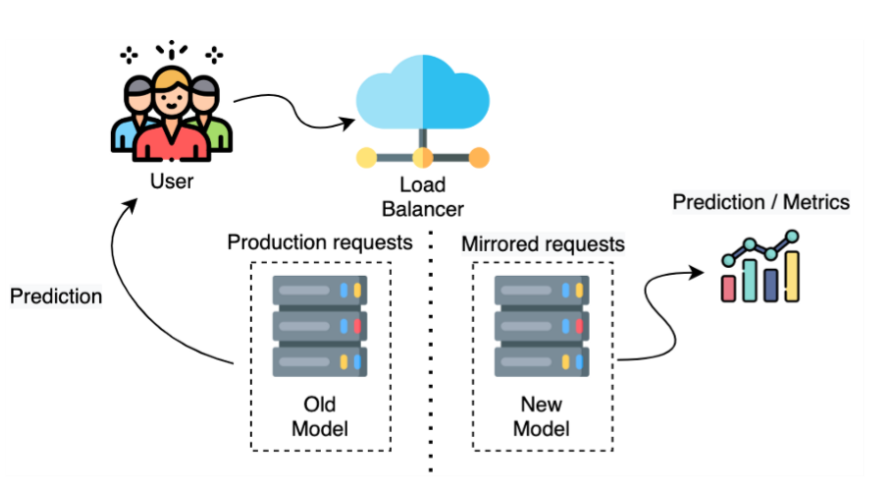
Shadow Deployment
Shadow Deployment requires the availability of an old version of the system already in place. so that in the initial phase of deployment , the new ML Model will not make any real decision and its predictions will not impact the users at all , alternatively it will run in parallel with the already existing system.
The purpose of the shadow deployment is to gather data about how is your new model performing in production and how it compares to the old one . and then verification of the new model output can take place , and therefore a decision can be taken if the new model is good enough to replace the old one in production or not.
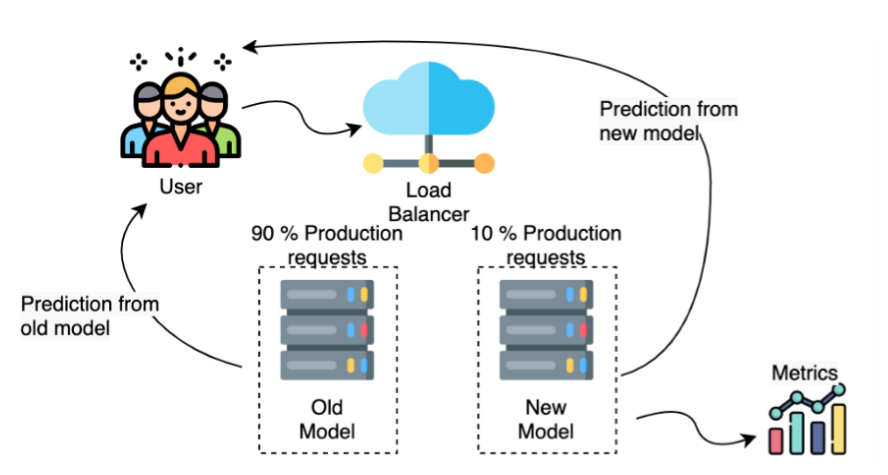
Canary Deployment
Instead of rolling out the model to the entire user base, only a certain user percentage is exposed to the new model. A typical starting split is for example 90/10 whereby 90% of the user requests are being handled by the old model and 10% are being exposed to the new model. If the new model contains a bug or the predictions are unsatisfactory, not all users will be affected but only a small subgroup — this minimizes risk.
The idea is again to collect key metrics of the new models’ performance over time. If the model turns out to run robustly, the share of users who are served by the new model can be increased step by step.
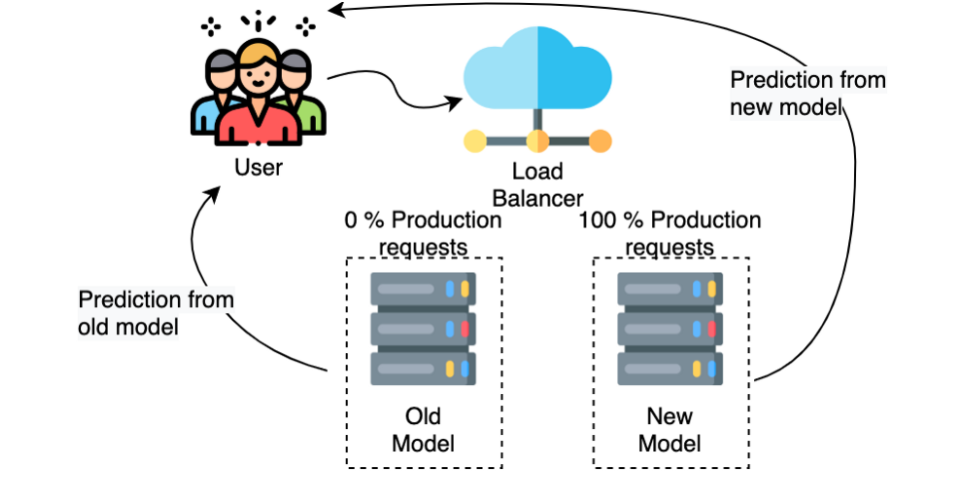
Blue/Green Deployment
The structure of the blue/green deployment is the same as the canary deployment (two models run in parallel), however, the main difference is that not only a share of the requests is being processed by the new model, but 100% of all requests are routed to the new model once it is up and running.
The idea is to simply have two environments that are as identical as possible: If something goes wrong with the new model, you can simply reroute all your requests to the old model (rollback).
Which Strategy should I use ?
In this section , I am going to compare the three mentioned deployment strategies against three points : Risk Reduction , Rollout and Rollback.
Risk Reduction : What is the impact on users in case of model failure?
- Shadow deployment : no negative impact on users at all.
- Canary deployment : a reduced negative impact on users , as the new model impacts only a small portion of the users.
- Blue/Green deployment : a huge impact on the users , as 100% of the traffic is routed to the new model.
Rollout : How fast is the roll out?
- Shadow deployment : Slow rollout , as the new model output should be verified for a while , before rolling out decision is taken
- Canary deployment: Slow rollout , as the share of users who are served by the new model are increasing gradually (step by step).
- Blue/Green deployment : Fast rollout . as the new model will handle 100% of the traffic once it’s placed in the production environment.
Rollback : How fast is the rollback?
- Shadow deployment : No rollback plan is needed, as the new model output is not affecting the users at all.
- Canary and Blue/Green deployments: Fast rollback , if the new model fails unexpectedly, you can roll back quickly to the old model, by simply redirecting all requests.
Choosing one of the mentioned strategies , or combining two of them or even creating a new strategy from scratch is only dependent on the business use case you are dealing with , so you need to create your personalized list of items to be considered during the deployment phase , then make sure that the chosen deployment strategy is robust enough to deal with these items.