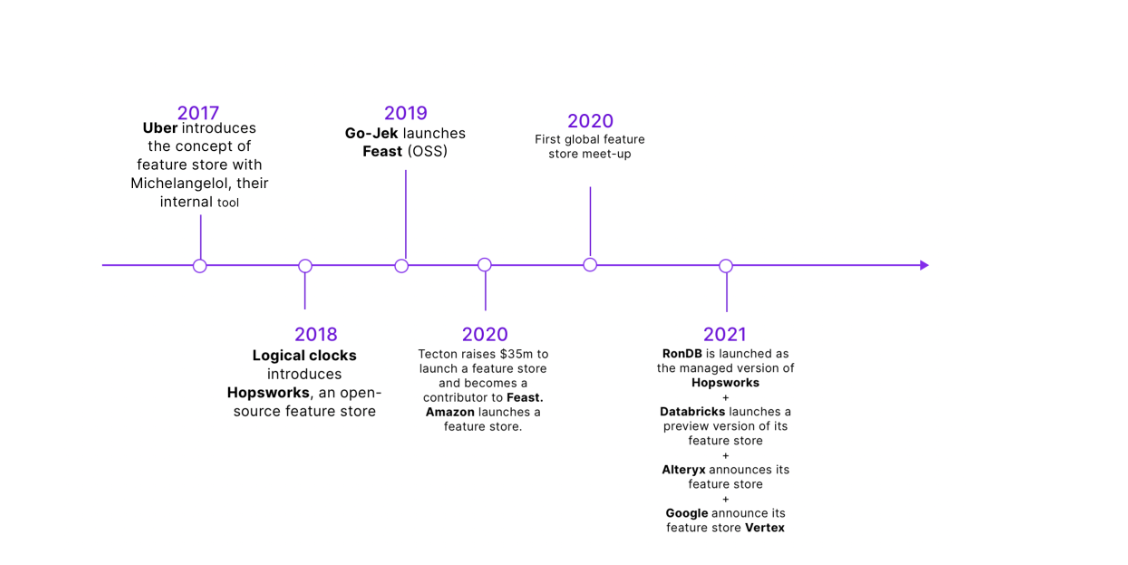
The whole story started when the feature store concept was introduced by Uber in 2017 with the launch of their Michelangelo platform. It is essentially a purpose-built data platform for machine learning features.
Fast forward a few years, and in less than two years, Hopsworks and Feast, two open-source feature store projects, were launched. Then tech giants such as Google (Vertex AI), Amazon (SageMaker), and Databricks were also quick to propose their own fully-managed feature store platforms.
What is a feature store?
As a starting point, to be able to answer this question, we need to primarily know what a feature is!
A feature is any measurable input that can be used in a predictive model—it could be the colour of an object, the sound of someone’s voice, the height of a person, etc.
For example, if we are building a predictive model for credit card fraud detection, features can be the total number of transactions, the total amount of the transactions, and the time elapsed between each two transactions, and these features will feed the model to be able to predict whether a credit card is fraudulent or not.
A Feature Store is a platform where all features are stored, centralized, and accessible to everyone for the explicit purpose of being used to either train models or make predictions.
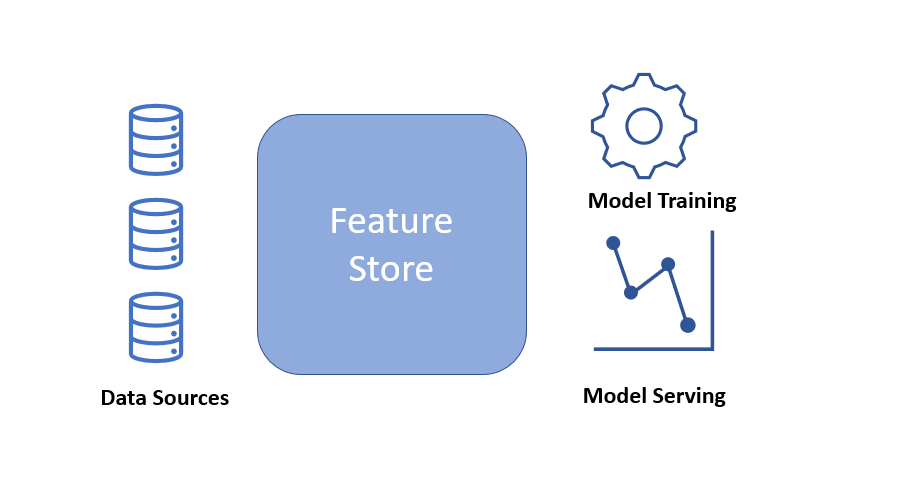
Why do we need a feature store?
1.Reuseability: That’s the key word and the main purpose of a feature store. It is simply the capability of reusing features across different machine learning models within the organization.
If you don’t reuse features across different models, you will end up with a new feature pipeline for each and every new model you put into production!
The Feature store prevents reinventing the wheel and developing a new data pipeline for each machine learning model by enabling the reuseability of the already existing features within the store.
This way, it massively reduces the number of data pipelines and limits the duplication of work.
2.Search and Discovery: In the building phase of a machine learning model, it is not expected to have a pre-defined list of the features that the model will leverage to generate predictions. Instead, there is a considerable amount of time and effort spent on discovering the features available and the metadata for each.
Most current commercial feature stores provide a visual user interface for browsing the feature catalog, and this allows teams to understand features better and determine if a feature is useful for a particular model or not.
Important Note: Features Discovery and Reusability are at the heart of the feature store, and the two capabilities are usually used together, so that the data scientist discovers the available features within the store and then decides to reuse them.
3.Decoupling ML Models from Data infrastructure: ML systems built on traditional data infrastructure are often strongly coupled to databases, object stores, streams, and files. A result of this coupling is that any change in data infrastructure may break dependent ML systems. The feature store decouples ML models from the data infrastructure by providing a single data access layer to access any needed feature for model serving or training.
4.Avoid Training serving Skew: Training-serving skew is a difference between performance during training and performance during serving. This skew can be caused for many reasons, but the most common reason is dual implementations of data retrieval for training and serving, which can lead to inconsistencies in data.
As models are trained on engineered datasets, it’s imperative to apply the same transformations to data sent for prediction. This often means rewriting feature engineering code, sometimes in a different language, integrating it into your prediction workflow, and running it at prediction time. This whole process is not only time-consuming, but it can also introduce inconsistencies as even the tiniest variation in a data transform can have a large impact on predictions. Feature Store is a good solution for the training-serving skew issue as The definitions of features used to train a model must exactly match the features provided for online serving .
The feature store lets you feed both training and inference with the same transformed feature values, ensuring consistency to drive more accurate predictions.
5.Avoid Data Leakage: Data Leakage is accidentally using data in model training that wouldn’t be available at the time of prediction.
Models with leakage perform unrealistically well in development, but they deliver poor model accuracy in production without the benefit of future data.
Data leakage usually happens with time-dependent features (a featue value that gets changed at a time after the time of generating the training label). Data scientists must ensure that the feature values are built only using data that was known before the target was observed. For example, if a label was generated at time t1, any feature value should be generated beyond t1, and this concept is called “Point in time features”.
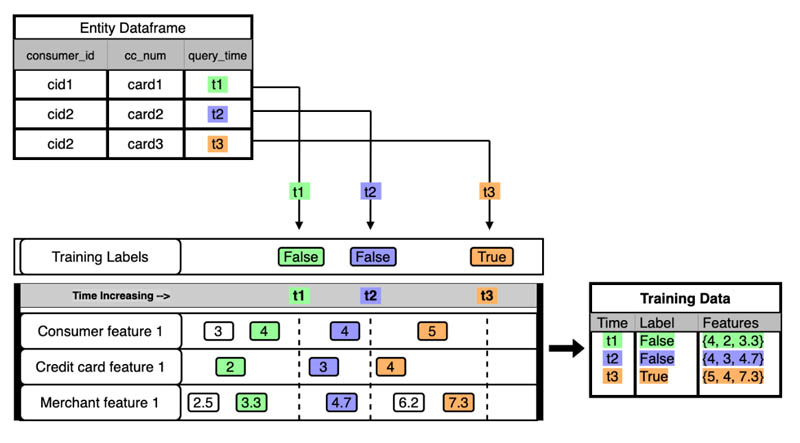
Let’s use the example and diagram from AWS Feature Store Blog to explain how feature store solves the data leakage issue.
Imagine we’re training a fraud detection model on a set of historical transactions.The features mostly concern the consumer, merchant, and credit card.and in this case, the feature values change over time.
To avoid leaking future feature values, a point-in-time query retrieves the latest state of each feature that was available at each transaction time and no later. For example, the transaction at time t2 can only use features available before time t2, and the transaction at t1 can’t use features from timestamps greater than t1.
Feature Store Main Components
The majority of commercial feature stores have five major components: registry, storage, transformation, monitoring, and user-facing SDK.
Registry Component
A centralised registry of feature definitions and metadata The registry acts as a single source of truth for information about a feature in an organization. It stores information like feature names, feature descriptions, and data types.
Storage Component
Feature stores persist feature data to support retrieval. They typically contain two layers of storage:
Online Storage Layer: persisted feature values for low-latency lookup during inference. They typically only store the latest feature values for each entity. They are usually implemented with key-value stores like DynamoDB, Redis, or Cassandra.
Offline Storage Layer : it is used to store months’ or years’ worth of feature data for training purposes. Offline feature store data is often stored in data warehouses or data lakes like S3, BigQuery, Snowflake, or Redshift.
Transformation Component
Feature stores both manage and orchestrate data transformations that produce the feature values. Transformations managed by feature stores are configured by definitions in the feature registry.
Monitoring Component
When something goes wrong in an ML system, it’s usually a data problem. Feature stores are positioned to detect data issues. They can calculate metrics on the features they store and serve that describe correctness and quality.
Feature data can be validated based on user-defined schemas or other structural criteria. Data quality is tracked by monitoring for data drift and training-serving skew.
User Facing SDK
The feature store represents a black box for the end user. The only way to access it is through a single interface (SDK) that contains methods to:
Manage feature definitions and metadata.
Ingest new data to the feature store.
Retrieve training datasets.
Retrieve online features.
How features are organized inside the feature store ?
To understand how features are organised inside the feature store, let’s first define some of the feature store’s important terms:
Entity: An entity is any domain object that can be modelled and about which information can be stored. such as people, places, things, or events.
Feature: A feature is any measurable property that can be used in a predictive model.
Features are the properties that describe the entities. For example, the number of transactions can be a feature for the entity credit card.
Feature Table: The logical grouping and schema of entities and related features.
One of the popular designs is to create one feature table for each entity, which contains all the features that describe this particular entity.
The Feature Store contains several ML Projects, and each ML project contains one or more feature tables, and each feature table contains one or more features that describe a certain entity or set of entities.
Summary
Feature stores, if not already ubiquitous, should be the next must-have step for every organisation that aims to build the best AI products without having to lose their bandwidth for operational purposes.
If you find yourself continually repeating efforts to code up feature transformations or copying and pasting feature-engineering code from project to project, a feature store could greatly simplify your life.
For more information about the feature store platforms, Feature Stores for ML Forum created a curated list of all the existing feature stores and a very detailed comparison between them.